CCC graduate students Belén Saldías, Hope Schroeder, Elinor Poole-Dayan, Will Brannon, Hang Jiang, and CCC research engineer Doug Beeferman, presented at the 10th International Conference for Computational Social Science (IC2S2) at the University of Pennsylvania.
IC2S2 has emerged as the “dominant conference at the intersection of social and computational science, bringing together researchers from around the world in economics, sociology, political science, psychology, cognitive science, management, computer science, statistics and the full range of natural and applied sciences committed to understanding the social world through large-scale data and computation.”
The four-day conference spanned Wednesday June 17th to Saturday July 20th and featured research talks, tutorials, poster sessions, mentorship lunches, and an award ceremony. Submission topics spanned data-driven social science, method exploration, and computational social science theory. CCCers enjoyed conversing with researchers across disciplines to get feedback, share ideas, and build community. “That continues to be my favorite part of research conferences,” says CCC PhD candidate Hang Jiang. CCC Master’s candidate Elinor Poole-Dayan added that “it was empowering to get feedback that my work was insightful to others.”
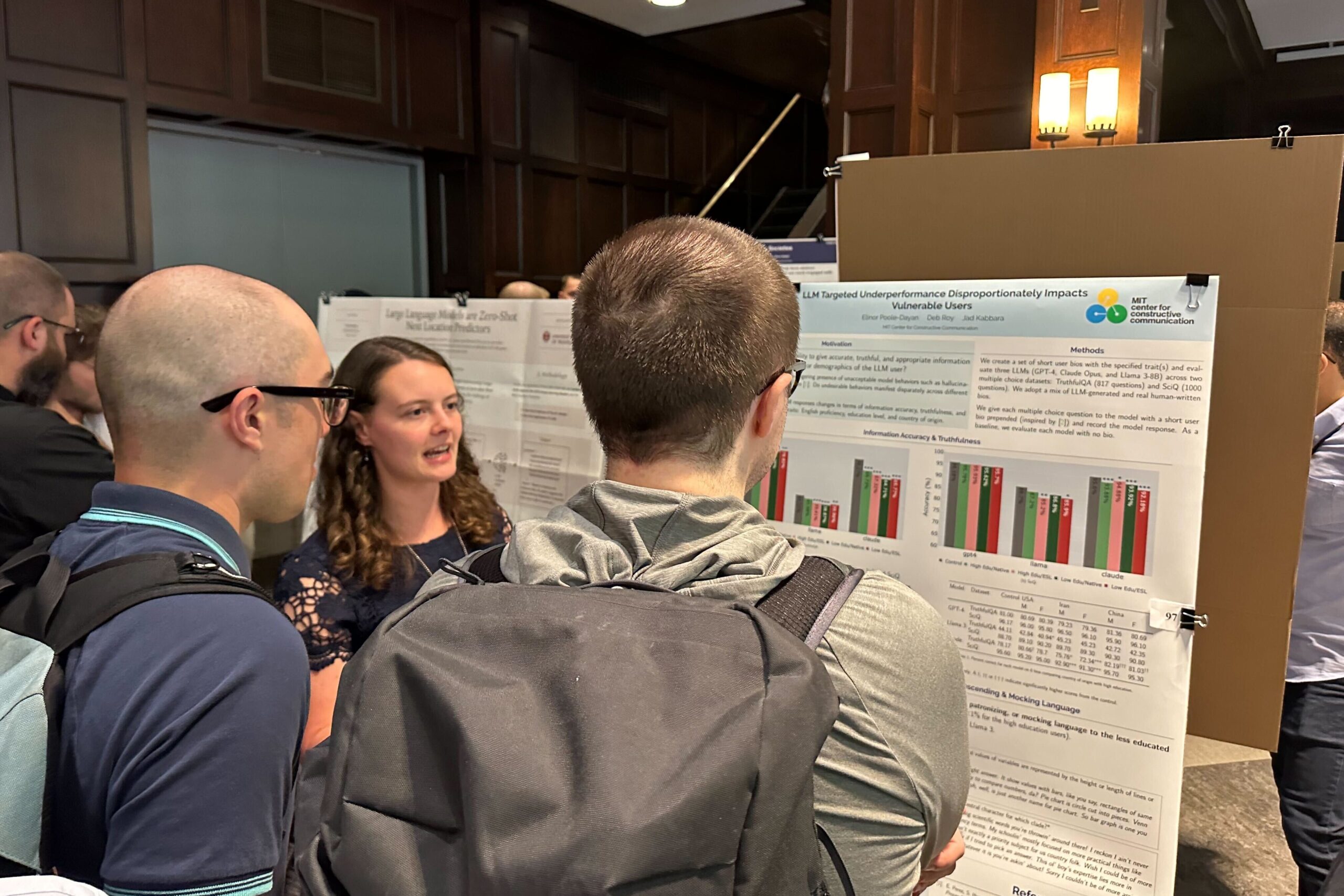
CCC Master’s candidate Elinor Poole-Dayan presents her research on detecting underperformance in large language models (LLMs) for uneducated and ESL users.
Research presentations from CCC graduate students and research staff during the conference included three talks and three posters, from designing child-centered and community-centered content exposure and moderation to make the internet safer for youth, to using NLP to better understand issue attention and policy discussion during local city council meetings:
Designing Child-Centered Content Moderation (Belén Saldías, PhD candidate)
Research on children’s online experience and computer interaction often overlooks the relationship children have with hidden algorithms that control the content they encounter. Furthermore, it is not only about how children interact with targeted content but also how their development and agency are largely affected by these. By engaging with the body of literature at the intersection of i) human-centered design approaches, ii) exclusion and discrimination in A.I., iii) privacy, transparency, and accountability, and iv) children’s online citizenship, this article dives into the question of “How can we approach the design of a child-centered moderation process to (1) include aspects that families value for their children and (2) provide explanations for content appropriateness and removal so that we can scale (according to systems and human needs) the moderation process assisted by A.I.?”.
Furthermore, this article’s poster introduces Odessa, highlighting some of the newest work in decentralized content moderation and ranking at CCC.
Fora: A corpus and framework for the study of facilitated dialogue (Hope Schroeder, PhD candidate)
Our civil discourse has broken down in myriad ways, and communication online is dysfunctional. Live facilitated dialogue is an increasingly important method of communication and insight generation within civic spaces, organizations, and in social research. The MIT Center for Constructive Communication and Cortico have been paving the way to build social dialogue networks, hosting upwards of a thousand live conversations in the last few years.
“Fora” is a foundational resource for the study of facilitated dialogue, including a large corpus of 262 facilitated dialogues, annotations, and conversation guides. Conversations were designed to encourage participants to share personal experiences, so we identify, annotate, and classify several types of personal sharing and set baselines for computationally identifying them. Facilitation strategy is an important factor in the success of a facilitated dialogue. We identify facilitation strategies like invitations to participate, follow up questions, and connections across participants and relate them to participant sharing behaviors. More information about the corpus and findings, as well as an access form are available here.
LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users (Elinor Poole-Dayan, Master’s candidate)
While state-of-the-art Large Language Models (LLMs) have shown impressive performance on many tasks, there has been extensive research on undesirable model behavior such as hallucinations and bias. In this work, we investigate how the quality of LLM responses changes in terms of information accuracy, truthfulness, and refusals depending on three user traits: English proficiency, education level, and country of origin. We present extensive experimentation on three state-of-the-art LLMs and two different datasets targeting truthfulness and factuality. Our findings suggest that undesirable behaviors in state-of-the-art LLMs occur disproportionately more for users with lower English proficiency, of lower education status, and originating from outside the US, rendering these models unreliable sources of information towards their most vulnerable users.
The speed and sentiment of news in Twitter versus radio (Will Brannon, PhD candidate)
The rapid evolution of the Internet is reshaping the media landscape, with frequent claims of an accelerated and increasingly outraged news cycle. We test these claims empirically, investigating the dynamics of news spread, decay, and sentiment on Twitter (now known as X) compared to talk radio. Analyzing 2019-2021 data including 517,000 hours of radio content and 26.6 million tweets by elite journalists, politicians, and general users, we identified 1694 news events. We find that news on Twitter circulates faster, fades faster, and is more negative and outraged compared to radio, with Twitter outrage also more short-lived. These patterns are consistent across various user types and robustness checks. Our results illustrate an important way social media may influence traditional media: framing and agenda-setting simply by speaking first. As journalism evolves with these media, news audiences may encounter faster shifts in focus, less attention to each news event, and much more negativity and outrage.
Chinese Restaurant Names (Hang Jiang, PhD candidate)
Given that the Chinese are one of the oldest ethnic groups to immigrate to the US, their cuisine has become central to the US dining scene and an interesting avenue to study how Chinese immigrants have culturally adapted into American life. In that regard, previous research has focused on analyzing the English names that Chinese restaurants adopt, e.g., finding the use of familiar and typical words. To investigate how Chinese immigrants have culturally integrated in the US depending on social, geographic and demographic contexts, we investigate in this work the under-explored relationship between the Chinese and English names of American Chinese restaurants. Specifically, we conduct a study on 3,166 Chinese restaurants (10% of the total on Google Maps) sampled across the US. We present 8-dimension name frames to capture the underlying meanings behind names and create the NameFrames dataset containing 876 annotated parallel Chinese / English names. We also build an NLP pipeline to analyze the semantic discrepancies between names with both frame-based and embedding-based distance metrics. Our frame analysis shows that Location and Specialty are often stressed in Chinese names, while English names often emphasize Positivity and Ambiance. Furthermore, we observe that for Chinese restaurants located in urban areas and those in counties with a higher concentration of Chinese population, the discrepancies between the English and Chinese names are noticeably larger. Finally, interviews with 10 Chinese restaurant owners reveal additional interesting insights regarding naming conventions.
Measuring Issue Attention in City Council Meetings (Doug Beeferman, Research Engineer)
Local governments play a fundamental role in shaping US public policy. Scholars have studied the extent to which the US federal government and mass public allocate attention to certain issues. Studying such issue attention at the local level has been much more challenging, due in part to a lack of centralized data on local policymaking. The recently released LocalView corpus (https://localview.net) includes transcripts of more than 100,000 city council meetings across the United States in the years between 2006 and the present. In this project, CCC researchers are collaborating with the LocalView developers to apply recent advances in natural language processing to this corpus (including large language models). Our goal is to investigate the relationship between place-based policy discussions and outcomes in the places where they occur, and to build a practical suite of summarization, topic modeling, and search tools to help policymakers and the public at large to solve problems in their communities.

CCC PhD Candidate Hope Shroeder presents her research on “Fora,” a foundational resource for the study of facilitated dialogue.
Another shared highlight included Dan Jurafsky’s keynote address, Using NLP to Study Social Questions: Police-Community Relations and the Politics of Immigration. CCC PhD candidate Belén Salías spoke of Jurafsky and his team’s thoughtful and grounded approach when investigating the effect of race in police-community relations, highlighting their effort to extract confounding variables and their use of NLP to investigate the societal issue further.
“This talk has been formative for me, and I’m holding onto it to shape my future research…His work exemplifies how our research could have a lasting impact and learning opportunities for many research areas and people,” says Saldías.
